Elasticsearch の Auto-Rebalancing を Docker で試す
Linuxど素人の Docker 入門第二弾です。 ちょっと Docker おもしろくなってきたかも。
Elasticsearch というのは、Apache Solr と並ぶ(むしろ Solr より流行ってきた?)全文検索システムなんですが、複数のサーバにデータを分散配置して並列処理やフェイルオーバーができたりします。
んで、Auto-Rebalancing というのは、サーバ(ノードというらしい)を追加した時に、そのサーバの役割が自動的に決まって、他のサーバからデータを分けて貰って、全体としてデータの平衡化が行われる事です。
Docker なら、サーバーの起動が容易なので、Auto-Rebalancing を試すのに持ってこいだと思い、やってみました。
全体的には、
を参考にしています。
ubuntu の Docker コンテナに Elasticsearch をインストール
昨日使った ubuntu のコンテナに Elasticsearch をインストールします。
Elasticsearch のインストールは、
を参考にしました。(なんか Elasticsearch を導入済みのコンテナとか Dockerfile もあったみたい)
次に、Elasticsearch の管理GUIを提供するプラグイン elasticsearch-head を導入します。
elasticsearch-head については、こちらがとても参考になりました。
インストールは、以下のコマンド一発です。(./ を付けないとうまく動いてくれなかった)
[ root@bb638d1f825f:/ ]$ cd elasticsearch/bin
[ root@bb638d1f825f:/ ]$ ./plugin -install mobz/elasticsearch-headElasticsearch のクラスタの設定
複数の Elasticsearch を動かす場合、共通のグループ名を付ける必要があります。
elasticsearch.yml を編集して、グループ名を付けます。
[ root@bb638d1f825f:/ ]$ vim elasticsearch/config/elasticsearch.yml//elasticsearch.yml
cluster.name: amayclusterElasticsearch の分散環境での使用については、
を参考にしました。
「EC2ではマルチキャストが使えない」などと書かれていますが、これは Docker なのでスルーで。結果的には elasticsearch.yml は上記の修正しかしていません。
Elasticsearch 設定済のイメージを作る
ここまでで一旦コンテナを終了し、docker commit で保存します。
docker images でイメージが作成できたのが確認できます。
docker@boot2docker:~$ docker commit -m "Setting Elasticsearch cluster" bb638d1f825f amay077/es_cluster
docker@boot2docker:~$ docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
amay077/es_cluster latest b9d05b77d71a 9 hours ago 1.075 GB
ubuntu latest ba5877dc9bec 2 weeks ago 192.7 MB複数の Docker コンテナを起動し、それぞれで Elasticsearch を起動する
下のようなコマンドで、コンテナを起動し、Elasticsearch を開始します。
(/bin/bash の代わりに直接 elasticsearch を開始してもよいと思いますが、後で直接コンソールに接続したいかなーと思いまして。)
docker@boot2docker:~$ docker run -i -t -p 9200:9200 -p 9300:9300 amay077/es_cluster /bin/bash
[ root@bb638d1f825f:/ ]$ /elasticsearch/bin/elasticsearch -d
#Control+p, Control+q でデタッチ1つ起動した時点で、ホストPC(Mac)のブラウザから http://localhost:9200/_plugin/head/ にアクセスします。 あ、その前に VirtualBox の設定で、9200と9300のポートフォワーディングを行う必要があります。
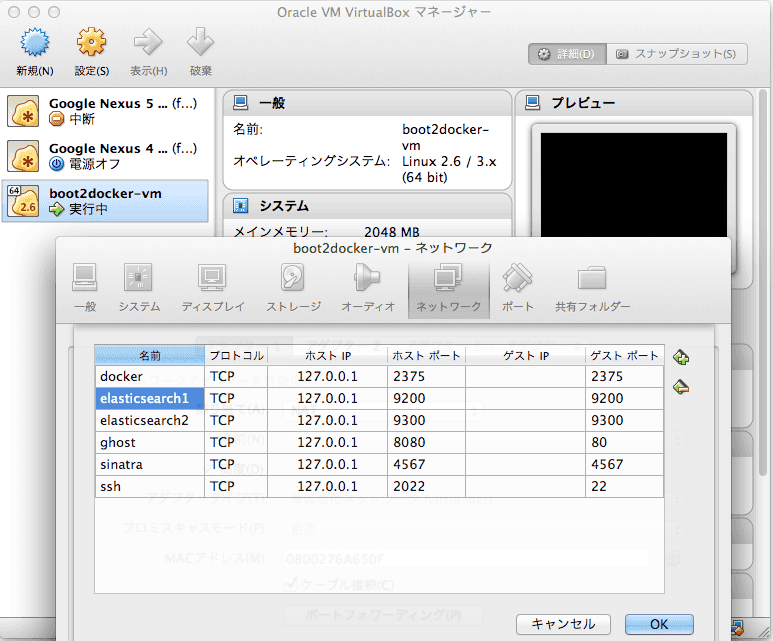
設定できたら先のアドレスにアクセスすると elasticsearch-head の管理画面が表示されるはずです。
続いて、さっきのコマンドを複数回実行し、複数の Elasticsearch を起動します。
-p 9200:9200 のところが重複するとエラーになるので -p 9201:9200 などとズラしましたが、これで正しかったのかわかりません。
Elasticsearch にデータ投入
Elasticsearch へのデータ投入は、ホストPC(Mac)の Terminal から、
curl -XPOST 'http://localhost:9200/mytest/memo/' -d '{ "name" : "kappa", "date" : "2013-09-07", "message" : "test1" }'
curl -XPOST 'http://localhost:9200/mytest/memo/' -d '{ "name" : "kappa", "date" : "2013-09-07", "message" : "test2" }'
curl -XPOST 'http://localhost:9200/mytest/memo/' -d '{ "name" : "kappa", "date" : "2013-09-07", "message" : "test3" }'
…続くのような感じで、3万件ほど投入しました。
投入後、 http://localhost:9200/_plugin/head/ を見ると、
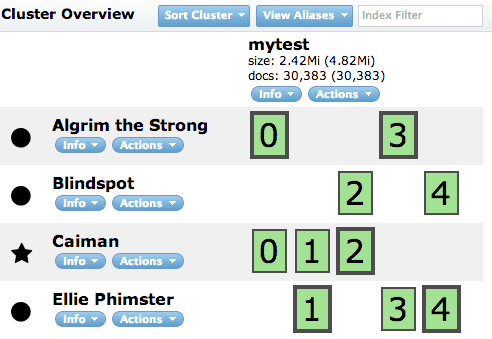
となっています。4台のサーバにデータが分散して登録されたことが分かります。四角内の数字(0〜4)は、「データが5つに分割され」て、その「ブロックがどのサーバに配置されているか」を示していて、太枠がプライマリ、細枠がスレーブであることを示しています。 いずれのサーバが死んでも、データの欠損なくサービス継続できることを示しています。
ノードを追加してみる
5台目の Elasticsearh を追加してみます。
docker@boot2docker:~$ docker run -i -t -p 9204:9200 -p 9304:9300 amay077/es_cluster /bin/bash
[ root@de6d825fa34d:/ ]$ /elasticsearch/bin/elasticsearch -d
#Control+p, Control+q でデタッチその後 elasticsearch-head を見ると、
となり、しばらくしてから Refresh すると、
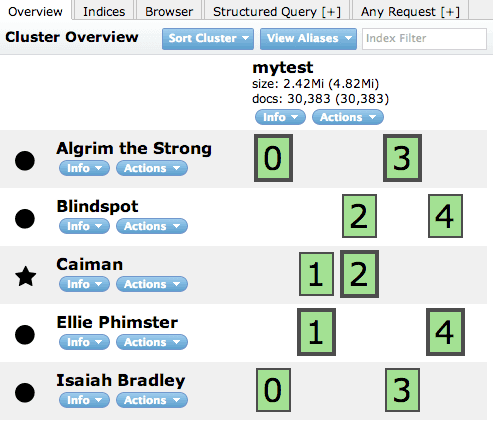
となります。
追加された「Isaiah Bradley」サーバには、データブロック1と3のスレーブの役割が与えられ、データが移動されたことが分かります。(移動中は色が変わったけどスクショ撮れなかった)
このように Elasticsearch の Auto-Rebalancing を、Docker を使うことでお手軽に試すことができました。(実運用では Elasticsearch に Docker は、、、使わないですよねたぶん)